
15. 아트라스로 구현한 데이터카탈로그
오픈소스를 사용하고, 자세히 분석하면서 느낀 점이 많다. 예전에는 많은 라이센스를 지불하고 구입했던 제품들이 이제는 저렴한 가격 혹은 심지어 무료로 이용이 가능하다. 개발을 할 수 있고 또는 사업 아이디어만 있다면 오픈소스와 클라우드를 사용해서 본인의 비즈니스와 스타트업으로 무엇이든 시도할 수 있다. 이스티오, 카프카, 아트라스, 레인저, CDAP, 쿠베플로우 등은 아주 우수한 오픈소스이고, 본인이 원하는 무엇이든 개발하고 사업을 할 수 있다. 바야흐로 진정한 4차산업혁명이고, 디지털 트랜스포메이션이다.
다년간 클라우드 프로젝트를 진행하면서 메타데이터의 중요성에 대해서 여러차례 느꼈다. 광범위하게 분산된 클라우드 원격 시스템을 구축하면서, 다양한 체계적인 관리의 필요성을 느꼈고 경험하였고, 데이터 영역에 극한되지 않고 인프라와 어플리케이션 개발 등 다방면에서 메타데이터는 활용되고, 전사적으로 구축되어야 한다고 생각한다.
AWS, GCP는 우수한 컴퓨팅 파워를 제공하지만 거버넌스를 위한 솔루션이 상대적으로 부족하다. 데이터 카탈로그와 모니터링 기능을 제공되지만 상용 혹은 오픈소스에 비해서 기능도 부족하다고 느낀 적이 많다.
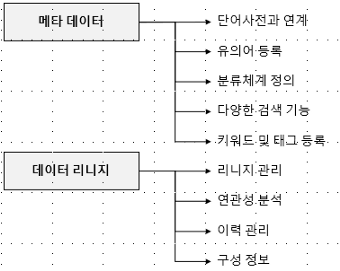
데이터 거버넌스를 위해서 관점에서 제한적으로 아트라스의 2가지 주요기능에 대해서 언급하면, 아트라스는 메타데이터와 데이터리니지 기능을 제공해야 한다. 아트라스는 우수한 메타 데이터와 데이터 리니지 기능을 제공한다.
아트라스는 하둡과 호환성이 좋지만, 클라우드 연계를 위해서는 추가적인 개발이 필요하다. 이러한 약점은 레인저도 유사하다. 하지만 아트라스는 추가적인 플러그인을 개발할 수 있도록 SDK를 지원하고, 클라우드 데이터 솔루션과 연계하고 기능을 확장할 수 있다. 특히 GCP는 플러그인을 제공한다. https://pypi.org/project/google-datacatalog-apache-atlas-connector/
아트라스 메타데이터
- 기업 내 사용되는 용어와 매칭시키는 작업이 필요한데, 아트라스에서는 유의어, 반의어, 용어 등을 포함하는 사전을 만들어서 용어를 관리할 수 있도록 도와준다
- 많은 용어와 태그를 관리하기 위해 분류 체계를 지원한다. 분류 구조를 만들어 다수의 메타를 체계적으로 관리할 수 있다.
- 검색엔진 수준의 메타 검색 기능을 제공한다. Solr를 사용해서 검색 기능을 제공하며, DSL을 지원하므로 복잡한 질의를 할 수 있다.
- 아트라스 내에서 정의되는 모든 객체에 태그를 사용하여, 추가적인 의미를 정의할 수 있고, 태그를 검색할 수 있는 기능을 제공한다.
- 레인저 등 접근 제어 솔루션과 연계가 가능하고, 데이터베이스 카프카 하이브 S3 등과 연계할 수 있다
- 객체 사이에 부모와 자식 관계, 연속된 값을 포함하는 배열 같은 복잡한 구조를 만들 수 있다.
- REST API와 자바 API를 제공하며, 이를 통해 타 어플리케이션과 연계하고 추가적인 커스머마이징이 가능하다.
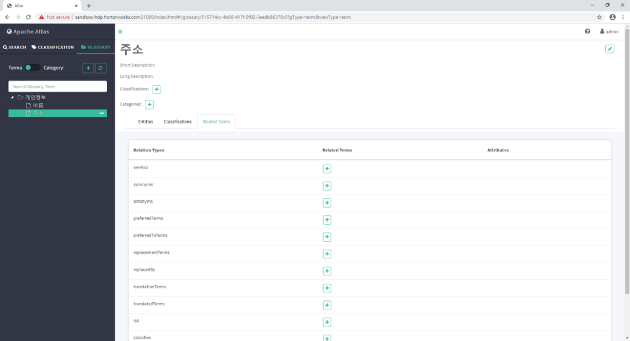
아트라스 데이터리니지
- 아트라스 데이터 리니지는 아트라스 내 정의된 메타데이터를 기반으로 리니지 기능을 제공한다. 리니지(lineage)와 영향(impact)으로 구성된다.
- 리니지는 파일, 데이터베이스 등에 영속적으로 저장되고 관리되는 대상이다.
- 영향은 글루, 아테나, 크롤러 등 일시적으로 잡을 처리하고 종료되는 대상이다.
- 메타와 리니지 수집이 종료되면 UI에서는 리니지가 생성한다. 리니지(lineage)와 영향(impact)의 순차적인 절차를 시각화한다
- 리니지와 연관성이 있는 대상을 분석할 수 있는 도식적인 화면을 제공하고, 이를 통해 상세한 리니지 정보를 분석할 수 있다.
- 리니지는 버전관리 기능을 제공하지 않으나, 이력관리 기능을 통해서 상세 분석 및 추적이 가능하다
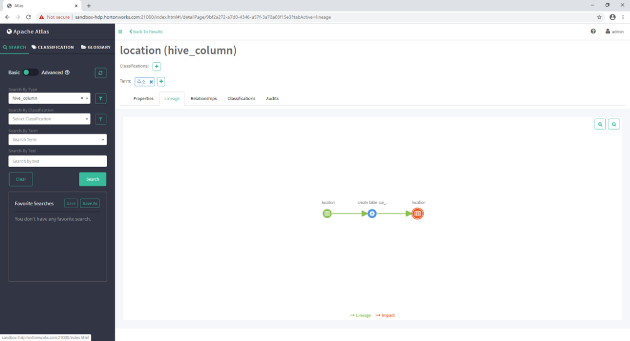
- 테이블, 컬럼 등의 구성정보를 관리한다. 리니지의 구조 및 구성 정보를 제공하며, 이를 통해 리니지의 이해도를 향상할 수 있다
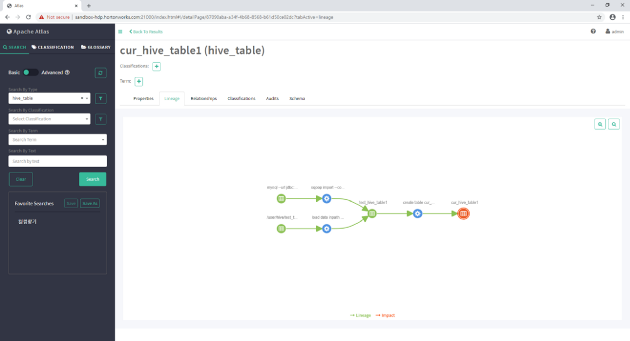
데이터옵스에서는 다양한 유형의 파이프라인이 정의한다. 대표적으로
- 데이터 파이프라인은 CDAP을 사용해서 구현되었다
빌드배포 파이프라인은 젠킨스로 구현되었다- 머신러닝 파이프라인은 쿠베플로우로 구현되었다
- 데이터 레이크는 빅쿼리를 사용한다.
다양한 데이터파인은 내부적으로 메타 정보를 활용하고 리니지를 생성한다. 지금의 메타 데이터와 리니지는 각 파이프라인 별로 분리되어서 운영되고, 이로 인해 전사 차원의 통합 거버넌스는 구축하기 어려운 것이 사실이다. 각 프로세스는 연결되고 흐름이 있는데 반해, 각 파이프라인 별로 다른 유형의 리니지를 생성한다. 다른 유형의 리니지를 이해하는 것도 쉽지 않을 뿐더러, 통합하는 것은 어려운 작업이다. 이로 인해 어렵게 만든 리니지 정보를 제대로 활용하지 못하게 된다.
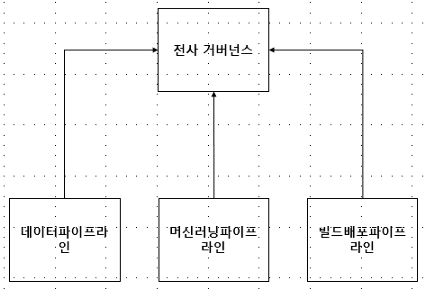
데이터옵스는 이러한 문제점을 인식하고, 아트라스 기반의 통합 거버넌스를 구축한다. 다양한 파이프라인의 메타 정보와 리니지 정보를 수집하여 통합하고, 이를 통해 통합 거버넌스를 구축할 수 있다.
아트라스와 레인저는 통합 거버넌스를 구축하기 위한 중요한 솔루션이다. 데이터옵스에서는 아트라스를 통해서 메타 데이터 및 데이터 리니지를 구현하고, 레인저를 통해서 정책관리 및 비식별화를 구현한다. 사용자 필요에 따라서 추가적인 커스터마이징을 손쉽게 할 수 있으며, 다양한 어플리케이션과 느슨하게 통합되어 있다
데이터 리니지 시나리오
아트라스는 자바 API와 REST API를 제공한다. API를 사용해서 아트라스는 AWS 메타와 연계하고 통합할 수 있다.
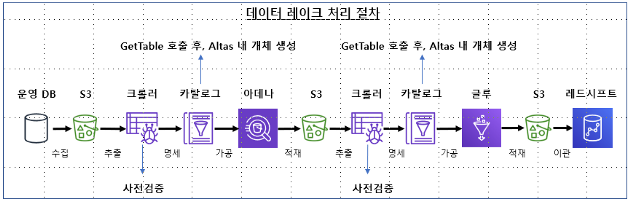
초기적재와 증감분 적재, 2가지 방안으로 AWS 데이터 카탈로그를 연계한다.
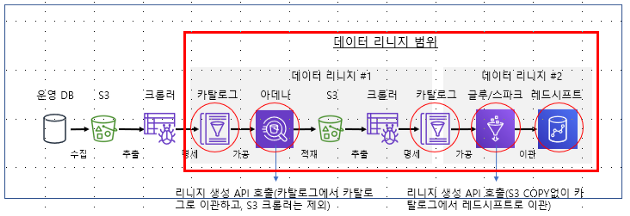
위의 그림은 오래 전에 아트라스를 발표하면서, 작성한 그림이다. 리니지를 잘 설명할 수 있는 현실적인 그림은
- 운영시스템에서 마스터 데이터를 관라히는 SQL
- 고객과 실시간으로 상호작용하는 캐시와 대용량 JSON을 처리하는 NoSQL, 비동기 메세징
- 분석시스템의 오브젝트 스토리지와 하둡의 HDFS
NoSQL이 스키마리스 구조인 경우에 리니지를 적용하는 쉽지 않은 경우가 많다. 그럼에도 불구하고 나중에 시간이 된다면, 위의 그림을 현실적으로 변경하도록 하겠다.
AWS 데이터 카탈로그와 아트라스를 연동하기 위해서, 아데나를 사용해 글루 데이터카탈로그 Information_schema에서 테이블과 컬럼 정보를 조회한다. 1번의 결과를 아트라스 API를 사용해서 아트라스에 메타데이터를 추가한다.
아래의 아데나 소스를 참고한다
const AWS = require('aws-sdk')
const Queue = require('async/queue')
const _ = require('lodash')const ATHENA_DB = 'cdw_mig_test1'
const ATHENA_OUTPUT_LOCATION = 's3://atlaslogphilip/'
const RESULT_SIZE = 1000
const POLL_INTERVAL = 1000let creds = new AWS.SharedIniFileCredentials({filename:'C:/Users/MZC01-YOHAIM/.aws/credentials', profile: 'default'});
AWS.config.credentials = creds;let client = new AWS.Athena({region: 'ap-northeast-2'})
/* Create an async queue to handle polling for query results */
let q = Queue((id, cb) => {
startPolling(id)
.then((data) => { return cb(null, data) })
.catch((err) => { console.log('Failed to poll query: ', err); return cb(err) })
}, 5);/* 아데나에서 글루 데이터 카탈로그의 테이블, 컬럼 메타를 추출 */
makeQuery("SELECT table_schema, table_name, table_type FROM information_schema.tables WHERE table_schema = 'cdw_mig_test1';")
.then((data) => {
console.log('Row Count: ', data.length)
console.log('DATA: ', data)
})
.catch((e) => { console.log('ERROR: ', e) })function makeQuery(sql) {
return new Promise((resolve, reject) => {
let params = {
QueryString: sql,
ResultConfiguration: { OutputLocation: ATHENA_OUTPUT_LOCATION },
QueryExecutionContext: { Database: ATHENA_DB }
}/* Make API call to start the query execution */
client.startQueryExecution(params, (err, results) => {
if (err) return reject(err)
/* If successful, get the query ID and queue it for polling */
q.push(results.QueryExecutionId, (err, qid) => {
if (err) return reject(err)
/* Once query completed executing, get and process results */
return buildResults(qid)
.then((data) => { return resolve(data) })
.catch((err) => { return reject(err) })
})
})
})
}function buildResults(query_id, max, page) {
let max_num_results = max ? max : RESULT_SIZE
let page_token = page ? page : undefined
return new Promise((resolve, reject) => {
let params = {
QueryExecutionId: query_id,
MaxResults: max_num_results,
NextToken: page_token
}let dataBlob = []
go(params)/* Get results and iterate through all pages */
function go(param) {
getResults(param)
.then((res) => {
dataBlob = _.concat(dataBlob, res.list)
if (res.next) {
param.NextToken = res.next
return go(param)
} else return resolve(dataBlob)
}).catch((err) => { return reject(err) })
}/* Process results merging column names and values into a JS object */
function getResults() {
return new Promise((resolve, reject) => {
client.getQueryResults(params, (err, data) => {
if (err) return reject(err)
var list = []
let header = buildHeader(data.ResultSet.ResultSetMetadata.ColumnInfo)
let top_row = _.map(_.head(data.ResultSet.Rows).Data, (n) => { return n.VarCharValue })
let resultSet = (_.difference(header, top_row).length > 0) ?
data.ResultSet.Rows :
_.drop(data.ResultSet.Rows)
resultSet.forEach((item) => {
list.push(_.zipObject(header, _.map(item.Data, (n) => {return n.VarCharValue })))
})
return resolve({next: ('NextToken' in data) ? data.NextToken : undefined, list: list})
})
})
}
})
}function startPolling(id) {
return new Promise((resolve, reject) => {
function poll(id) {
client.getQueryExecution({QueryExecutionId: id}, (err, data) => {
if (err) return reject(err)
if (data.QueryExecution.Status.State === 'SUCCEEDED') return resolve(id)
else if (['FAILED', 'CANCELLED'].includes(data.QueryExecution.Status.State)) return reject(new Error(`Query ${data.QueryExecution.Status.State}`))
else { setTimeout(poll, POLL_INTERVAL, id) }
})
}
poll(id)
})
}function buildHeader(columns) {
return _.map(columns, (i) => { return i.Name })
}아트라스에서 제공하는 일반적인 데이터 리니지 절차는 아래와 같다
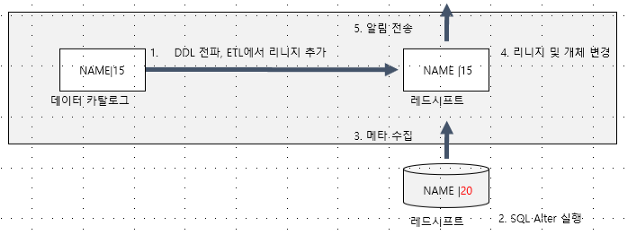
데이터 엔지니어라면 스키마 변경작업의 어려움을 이해할 것이다. 리니지를 유용하게 활용할 수 있는 분야가 바로 스키마 변경이다. 아트라스에서는 DDL 전파를 통해서 스키마 변경에 대한 범위와 대상을 이해할 수 있도록 도와준다. UI에서는 설정 기능을 제공해 주고, 추가적인 API를 통해서 개발과 커스터마이징이 가능하다.
아래의 이미지 수정이 필요하다.
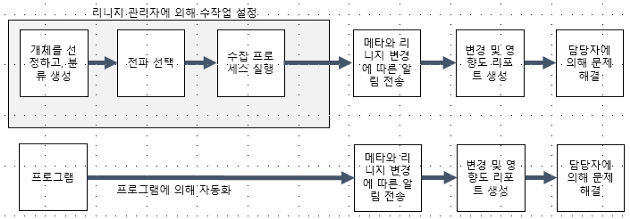
아래처럼 REST API를 사용한다 아래의 예제는 리니지를 생성하는 REST API명세이다
아트라스의 모든 CRUD는 API를 통해서 이루어진다
즉 아트라스는 AWS, GCP, 하이브 메타스토어 등 다양한 데이터 카탈로그를 통합하는 방안을 제공하고, 통합 거버넌스 플랫폼을 구축할 수 있다.
아트라스 REST API
아트라스 아키텍처를 리뷰하면, HBase를 사용하여 메타데이터를 관리한다. 검색에는 Solr 고가용성을 위해서 주키퍼를 사용한다. 다른 시스템과 연계 시 HBase와 직접적인 연계가 불가능하다. 즉 데이터베이스를 통한 연계 기능은 제공되지 않는다.
아트라스 REST API를 배우는 방법은, 샘플을 분석하고 이해하라고 권장하고 싶다. CURL을 사용해서 유형, 개체, 리니지 등을 조회하면 기본적인 구성을 이해할 수 있으므로, 템플릿을 만든 다음에 각자가 원하는 수준으로 커스터마이징을 하면 쉽게 REST API를 사용할 수 있다.
17–11
유형를 생성하는 REST API는 아래와 같다
{
"entityDefs" : [
{
"superTypes" : [ "kafka_topic" ],
"category": "ENTITY",
"name": "",
"description": "create column entity",
"typeVersion": "1.0",
"attributeDefs": [
{
"name" : "database",
"typeName" : "server",
"isOptional" : false,
"cardinality" : "SINGLE",
"valuesMinCount" : 1,
"valuesMaxCount" : 1,
"isUnique" : false,
"isIndexable" : true
},
{
"name": "data_type",
"typeName": "string",
"isOptional": false,
"cardinality": "SINGLE",
"valuesMinCount": 1,
"valuesMaxCount": 1,
"isUnique": false,
"isIndexable": true
},
{
"name": "comment",
"typeName": "string",
"isOptional": false,
"cardinality": "SINGLE",
"valuesMinCount": 1,
"valuesMaxCount": 1,
"isUnique": true,
"isIndexable": true
},
{
"name" : "table",
"typeName" : "",
"isOptional" : false,
"cardinality" : "SINGLE",
"valuesMinCount" : 1,
"valuesMaxCount" : 1,
"isUnique" : false,
"isIndexable" : true
}
]
},
{
"superTypes" : [ "kafka_topic" ],
"category" : "ENTITY",
"name" : "",
"description" : "create table entity",
"typeVersion" : "1.0",
"attributeDefs" : [
{
"name" : "database",
"typeName" : "server",
"isOptional" : false,
"cardinality" : "SINGLE",
"valuesMinCount" : 1,
"valuesMaxCount" : 1,
"isUnique" : true,
"isIndexable" : true
},
{
"name" : "key_schema",
"typeName" : "array<>",
"isOptional" : true,
"cardinality" : "SINGLE",
"valuesMinCount" : 1,
"valuesMaxCount" : 1,
"isUnique" : true,
"isIndexable" : true
},
{
"name" : "value_schema",
"typeName" : "array<>",
"isOptional" : true,
"cardinality" : "SINGLE",
"valuesMinCount" : 1,
"valuesMaxCount" : 1,
"isUnique" : true,
"isIndexable" : true
}
]
}
]
}개체를 생성하는 REST API는 아래와 같다. REST를 사용해서 복잡한 다계층 부모와 자식 객체를 생성하는 것이 복잡하다. 이 경우에는 자바 API를 사용하는 것을 권장한다.
17–4
{
"entities": [
{ "typeName": "","guid":-500,
"createdBy": "",
"attributes": {
"qualifiedName": "id",
"uri": "",
"name": "id",
"topic":"customer",
"database" : {"guid": -100,"typeName": "server"},
"data_type": "string",
"comment": "식별자",
"table" : {"guid": -600,"typeName": ""}
}
},
{ "typeName": "","guid":-501,
"createdBy": "",
"attributes": {
"qualifiedName": "address",
"uri": "",
"name": "address",
"topic":"customer",
"database" : {"guid": -100,"typeName": "server"},
"data_type": "string",
"comment": "주소",
"table" : {"guid": -600,"typeName": ""}
}
},
{ "typeName": "","guid":-502,
"createdBy": "",
"attributes": {
"qualifiedName": "contact",
"uri": "",
"name": "contact",
"topic":"customer",
"database" : {"guid": -100,"typeName": "server"},
"data_type": "string",
"comment": "연락처",
"table" : {"guid": -600,"typeName": ""}
}
},
{ "typeName": "","guid":-503,
"createdBy": "",
"attributes": {
"qualifiedName": "company",
"uri": "",
"name": "company",
"topic":"customer",
"database" : {"guid": -100,"typeName": "server"},
"data_type": "string",
"comment": "직장",
"table" : {"guid": -600,"typeName": ""}
}
},
{ "typeName": "","guid":-504,
"createdBy": "",
"attributes": {
"qualifiedName": "birthday",
"uri": "",
"name": "birthday",
"topic":"customer",
"database" : {"guid": -100,"typeName": "server"},
"data_type": "number",
"comment": "생년월일",
"table" : {"guid": -600,"typeName": ""}
}
},
{ "typeName": "","guid":-600,
"createdBy": "",
"attributes": {
"qualifiedName": "customer",
"uri": "",
"name": "customer",
"topic":"customer",
"description": "고객 테이블",
"owner": "스키마명",
"database" : {"guid": -100,"typeName": "server"},
"key_schema":[
{ "typeName": "","guid":-500 }
],
"value_schema":[
{ "typeName": "","guid":-500 },
{ "typeName": "","guid":-501 },
{ "typeName": "","guid":-502 },
{ "typeName": "","guid":-503 },
{ "typeName": "","guid":-504 }
]
}
}
],
"referredEntities": {
"-100": {
"guid": "-100",
"typeName": "server",
"attributes": {
"qualifiedName": "",
"uri": "",
"name": "",
"dns_name": "",
"ip_address": "10.71.68.93"
}
}
}
}관계를 생성하는 REST API는 아래와 같다. inputToProcesses, outputFromProcesses 만 생성이 된다. 이 예제에서는 schema, sd, columns, meanings, db 는 생성이 안된다. 즉 개체에 따라서 필요로 하는 relationshipAttributeDefs는 다르다.
"relationshipAttributeDefs": [
{
"name": "schema",
"typeName": "array<avro_schema>",
"isOptional": true,
"cardinality": "SET",
"valuesMinCount": -1,
"valuesMaxCount": -1,
"isUnique": false,
"isIndexable": false,
"includeInNotification": false,
"relationshipTypeName": "avro_schema_associatedEntities",
"isLegacyAttribute": false
},
{
"name": "inputToProcesses",
"typeName": "array<Process>",
"isOptional": true,
"cardinality": "SET",
"valuesMinCount": -1,
"valuesMaxCount": -1,
"isUnique": false,
"isIndexable": false,
"includeInNotification": false,
"relationshipTypeName": "dataset_process_inputs",
"isLegacyAttribute": false
},
{
"name": "meanings",
"typeName": "array<AtlasGlossaryTerm>",
"isOptional": true,
"cardinality": "SET",
"valuesMinCount": -1,
"valuesMaxCount": -1,
"isUnique": false,
"isIndexable": false,
"includeInNotification": false,
"relationshipTypeName": "AtlasGlossarySemanticAssignment",
"isLegacyAttribute": false
},
{
"name": "outputFromProcesses",
"typeName": "array<Process>",
"isOptional": true,
"cardinality": "SET",
"valuesMinCount": -1,
"valuesMaxCount": -1,
"isUnique": false,
"isIndexable": false,
"includeInNotification": false,
"relationshipTypeName": "process_dataset_outputs",
"isLegacyAttribute": false
}
]
리니지를 생성하는 REST API는 아래와 같다.
{
"entities": [
{
"typeName": "",
"attributes": {
"qualifiedName": "",
"uri": "",
"name": "",
"id": "",
"inputs": [
{
"guid": "",
"typeName": ""
}
],
"outputs": [
{
"guid": "",
"typeName": ""
}
]
}
}
]
}아트라스를 백엔드로 사용하고, 프론트엔드를 포탈 형식으로 개발해서 솔루션화한 경험이 있다. 아트라스UI가 고객사의 요구사항과 적합하지 않은 반면에. 우수한 아키텍처와 API가 제공된다. 아트라스를 커다란 DB라고 생각해서 REST API를 통해서 CRUD를 처리하고, 프론트엔드를 기존 포탈과 통합하는 것도 좋은 아이디어라고 생각한다.
다양한 데이터 소스와 연계
데이터베이스의 메타를 반입하기 위해서, 스쿱을 사용하는 것보다는 데이터베이스의 메타정보를 REST API로 호출하는 것을 권장한다. 스쿱의 시나리오는 아래와 같다
- 데이터베이스에서 하이브
- 하이브에서 데이터베이스
스쿱을 사용해서 데이터베이스에서 곧바로 메타데이터를 반입하는 것은 적합하지 않다. 스쿱은 DB를 사용하는 경우에는 유용하지만 데이터소스가 다른 경우에는 활용이 어렵다. 다양한 DB를 지원하기 위해서 GCP에서 개발한 아트라스 어댑터를 커스터마이징해서 사용할 수 있다.
S3 오브젝트 스토리지는 스키마 정보를 제공하지 않기 때문에, AWS S3 변경 시에 변경분을 트리거하는 로직을 자체 개발할 수도 있지만, 클라우데라는 이미 오픈소스로 제공한다. 기본적으로 크롤러와 데이터 카탈로그를 실행하고 아트라스로 반출한다. 다른 방안은 하이브 외부 테이블로 변환한 다음에 아트라스에서 관리하는 것을 권장한다.
S3 오브젝트 스토리지에는 태그를 통해서 추가적인 정보를 기술할 수 있다. 이는 데이터베이스의 주석과 유사하다. 그러나 아트라스로 반입이 복잡하다. 태그와 주석은 명명규칙과 채번을 적용할 수 있다. 아트라스 내부적으로 부가적인 설명과 분류, 태그 등을 추가할 수 있으므로 일관성 있게 관리해야 한다. AWS가 아닌 다른 클라우드를 사용하더라도 비슷한 방식으로 연계가 가능하다.
AWS 데이터 카탈로그에서 레드시프트를 크롤링해서 데이터 카탈로그를 관리하는 것이 일반적이다. AWS 데이터 카탈로그와 아트라스를 연계해서 통합 데이터 카탈로그 구현이 가능하다.
메타와 리니지의 주요 범위는 하이브(오브젝트 스토리지), 스파크, 카프카, 클라우드 데이터 카탈로그, 데이터 베이스, CDAP, 쿠베플로우를 권장한다.
근래 발표된 오픈소스인 DataHub는 상당히 우수한 메타데이터와 리니지 오픈소스인 것으로 판단된다. 시간이 허락된다면 공부해 보고 싶다. 아트라스의 단점은 비교적 적은 수의 어댑터를 제공한다는 점이다. 요즘은 NoSQL을 많이 사용한다. 아트라스는 NoSQL 레디스 몽고를 지원하지 않는다는 점이다. NoSQL은 스키마리스인 경우가 대부분인데, 스키마가 원래 없음에도 불구하고 스키마를 구조화해서 관리한다는 점이 쉽지 않은 것도 사실이다. 데이터허브는 몽고 등 훨씬 많은 어댑터를 제공하므로 문제점을 해결할 수 있다.
복잡한 구조를 관리하는 것이 어렵다. 다계층 객체와 복합한 포함 관계를 가진 배열 등을 아트라스 형식으로 만들 경우에 시간이 많이 걸린다. 조금 더 쉬운 방법이 제공되었으면 하는 바램이 있다.